
The 10 GitHub Repos AI Engineers Use to Make LLMs Faster and Cheaper
A practical stack for optimizing inference speed, memory usage, and GPU efficiency in real-world LLM systems

If you work with LLMs long enough, you realize something uncomfortable.
Model quality is rarely the bottleneck.
Performance is.
Latency, memory pressure, and GPU utilization decide whether a system ships, scales, or quietly gets rewritten. The engineers who deal with this every day tend to converge on a smaller, more opinionated toolset.
Here are 10 repos that show up again and again when speed, memory efficiency, and real-world deployment matter. Reordered on purpose. This is how people actually encounter them in practice.
1) llama.cpp (⭐92k)

Many journeys start here.
llama.cpp set the baseline for what efficient inference looks like on consumer hardware. Written in C and C++, aggressively optimized, and endlessly forked, it powers a huge part of the local LLM ecosystem.
If you care about squeezing performance out of limited hardware, this repo teaches you more than most papers.
2) vLLM (⭐66k)
Eventually, traffic arrives.
vLLM has become the default answer to high-throughput LLM serving. Continuous batching and smarter memory management translate directly into higher GPU utilization and lower cost per request.
This is where teams land when demos turn into real products.
3) PyTorch (⭐96k)

When abstractions stop helping, you drop down a level.
PyTorch remains the core framework for custom optimization, research-heavy work, and anything that does not fit neatly into existing serving stacks. Kernels, memory layout, experimental architectures all start here.
It is slower to work with. It is also unavoidable.
4) Hugging Face Transformers (⭐154k)

The connective tissue of the ecosystem.
Almost every serious LLM workflow touches Transformers at some point. Prototyping, benchmarking, fine-tuning, or integration usually starts here, even if production ends somewhere else.
Not always the fastest path, but still the most universal one.
5) Ollama (⭐160k)

The fastest way to get unstuck.
Ollama trades ultimate performance for an extremely clean developer experience. That tradeoff is often correct early on. You get models running locally in minutes, not hours.
Great for experimentation and quick iteration before performance tuning matters.
6) FlashAttention (⭐21k)
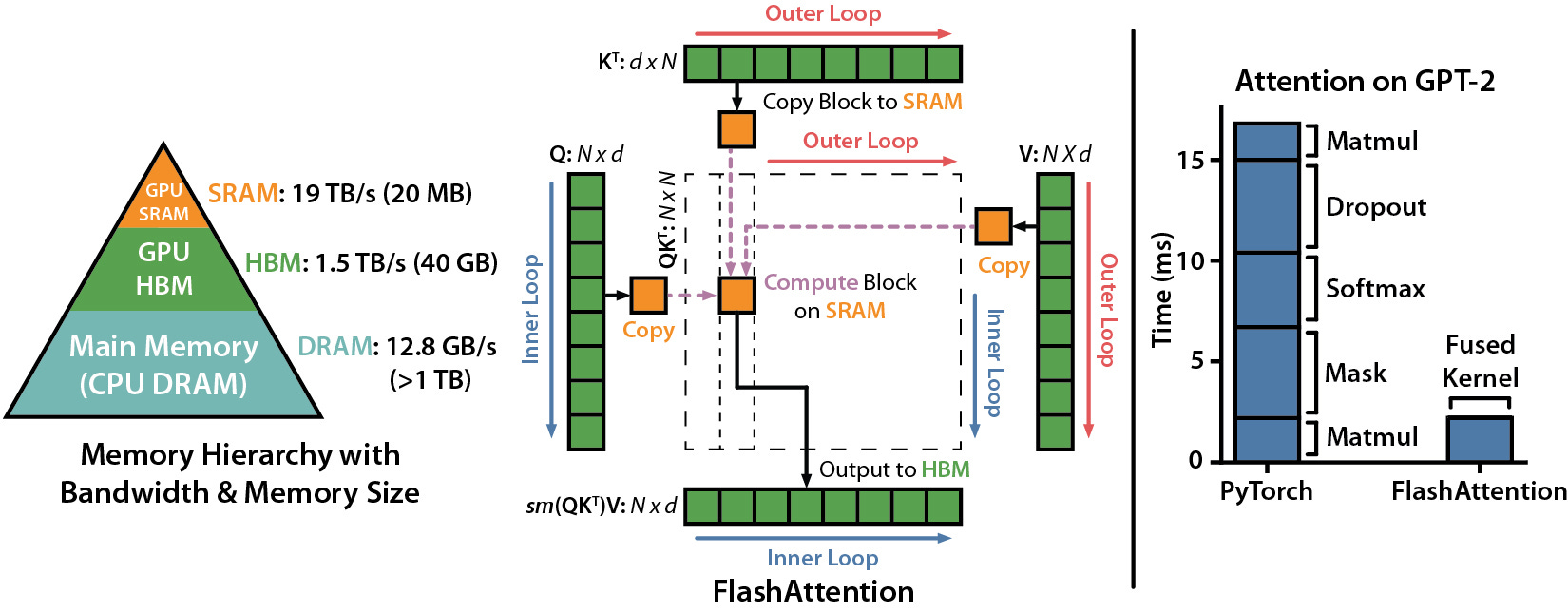
You might not call it directly, but you rely on it.
FlashAttention delivers large gains in speed and memory efficiency at the attention layer. Many higher-level tools depend on it under the hood.
Understanding this repo explains why some systems scale smoothly while others fall apart.
7) Unsloth (⭐50k)

Fine-tuning without burning VRAM.
Unsloth focuses on making LLM fine-tuning faster and significantly more memory-efficient. That matters when you want custom models but do not want to scale infrastructure just to experiment.
Especially useful for small teams moving quickly.
8) MLC LLM (⭐22k)
Performance through compilation.
MLC LLM takes a different approach by compiling models to run efficiently across different platforms. The goal is portability with predictable performance characteristics, rather than hand-tuning everything.
A strong option when hardware diversity matters.
9) FastChat (⭐39k)
A flexible middle ground.
FastChat supports training, serving, and evaluating chat systems and is widely used in research and early production setups. It offers more structure than ad-hoc scripts without locking you into a rigid framework.
Good for teams still exploring product shape.
10) whisper.cpp (⭐45k)

Performance lessons beyond text.
whisper.cpp shows how far careful C and C++ optimization can go for real workloads. Fast, local speech-to-text without cloud dependencies.
Even if you do not work with audio, it is a useful reference for performance-first design.
The pattern behind the list
The biggest gains in LLM systems come from batching strategies, memory layout, attention efficiency, compilation, and hardware-aware execution. The repos above sit exactly at that layer.
If you are serious about shipping LLMs, you eventually assemble some version of this stack. Not because it is trendy, but because it is where performance actually gets unlocked.
If you would add or remove something, that usually says a lot about where your bottlenecks really are.
This piece realy made me think, and it totally complements your previous insights on LLM deployment, showing how crucial real-world performance is for shipping products.
We should mention CascadeFlow here (📌 https://github.com/lemony-ai/cascadeflow) — it’s a useful open-source model cascading tool that can cut costs and improve latency by automatically selecting cheaper models when appropriate.