
The Agency Owner Who Stopped Writing Proposals and Started Printing Them
What actually separates consultants charging $500/month from the ones charging $50,000

1 month ago I had a conversation with a consultant who runs a small growth agency.
8 clients. 2 full-time people. Revenue that would embarrass most 10-person shops.
I asked him what changed. He said 1 thing:
he stopped treating AI like a writing assistant and started treating it like a production system
His team now runs 15 specialized Claude Code agents to build go-to-market packages for B2B clients. The kind of work that used to take 2 weeks. The pipeline does it in 4 hours.
He raised his prices 4x. His close rate went up. He works fewer hours.
This is how he built it.
Why a single prompt always underperforms

When you open Claude and type a request, you’re asking one thing to do ten jobs simultaneously.
Research. Positioning. Writing. Quality control. Editing. Scoring. All at once.
No single person does all of that well in one sitting. A single prompt doesn’t either. What comes out is a reasonable first draft at best — limited context, no real research, nothing enforcing quality at any stage.
The system this consultant built does the opposite at every step.
The architecture in plain terms
Fifteen agents. Each one does exactly one job. Each lives in its own context window. Each has a quality gate it has to clear before anything moves forward.
You give it a company name, a target customer, and a goal. You walk away. You come back to a complete, research-backed deliverable ready to present.
The research phase alone is what most agencies skip.

Before any writing starts, the system pulls top-performing content across three time windows, extracts verbatim customer language from communities where the target buyer actually spends time, and maps the competitive landscape. Everything gets indexed as context for every agent that runs after it.
Then the writing pipeline runs in sequence. Positioning agent. Messaging agent. Copy agent. Each one with a manager that scores the output and sends it back if it doesn’t clear.
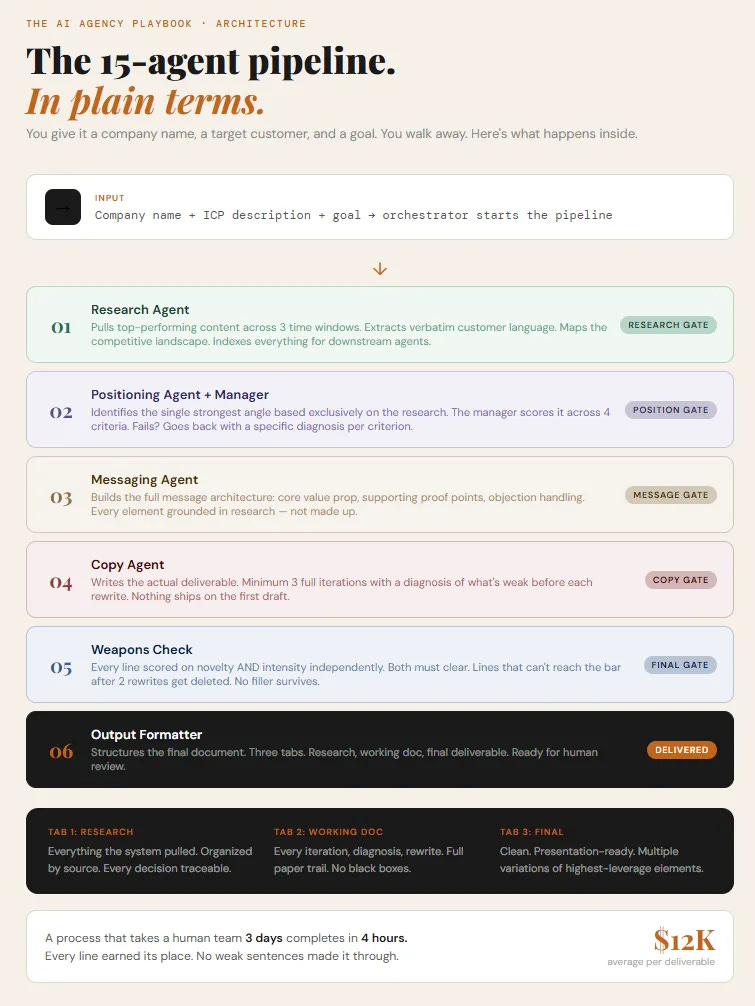
And at the end, every single line gets scored on two things independently: does it make the product feel genuinely different, and is it sharp enough that someone reading it actually feels something rather than just understands something.
Lines that don’t clear both get rewritten. Lines that can’t be saved get deleted.
The deliverable that comes out has no weak lines. Every sentence earned its place.
Most people read something like this and don’t build anything. The ones who do build it charge 4x what they charged before.
What’s inside the full guide:
The complete agent architecture: every agent, its exact job, and its specific cannot-do list. Copy it directly into Claude Code.
The 7 quality gate templates: the exact scoring criteria for each stage. Paste these in and your agents hold a higher standard than most human editors.
The full orchestrator prompt: the coordinator agent that manages the entire pipeline and enforces every handoff.
The research infrastructure setup: which APIs, how to wire them, and the Claude Code prompt that builds the scrapers for you.
The pricing framework: how to calculate what to charge based on what the output is actually worth, and the three models that work.
The five use cases generating the most revenue right now: outreach sequences, investor materials, SEO content, product launches, and market research. With specific pipeline variations for each.
The one-week build plan: exactly what to build on day one, day three, and day seven to have a working system by the end of the week.
The AI Playbook:
Keep reading with a 7-day free trial
Subscribe to The AI Corner to keep reading this post and get 7 days of free access to the full post archives.