
Claude OPUS 4.7 is here. Here is what actually changed
Same price. Better coding. 3x the vision. A new effort level. The full breakdown in one place

Anthropic shipped Claude Opus 4.7 today
Same price as Opus 4.6. $5 per million input tokens, $25 output.
Available everywhere: claude.ai, the API, Bedrock, Vertex AI, Microsoft Foundry.
Four things changed in a meaningful way:

Speaking of inference costs: the Opus 4.7 migration raises a question most AI founders struggle to answer cleanly:
What is your cost per inference call in production?
Training costs, GPU bills, API spend: most teams track those. But the per-call unit economics of actually serving a product at scale? Usually fuzzy. That number is what separates companies that scale from ones that plateau.
Deploy by DigitalOcean is a free one-day conference in San Francisco on April 28 built entirely around answering it:

Character AI’s Chief Architect, Workato’s AI Research Lead, and CEOs from VAST Data, Arcee, and vLLM are all presenting real architectures, real cost data, and live demos of how they actually run inference in production.
If you are building AI products and this number keeps you up at night, this is the most useful afternoon you will spend this month 👇
The numbers first:
SWE-bench Verified: 87.6% vs 80.8% on Opus 4.6
SWE-bench Pro: 64.3% vs 53.4%
Computer use (OSWorld): 78.0% vs 72.7%
Visual reasoning (CharXiv): 82.1% vs 69.1%
Financial analysis: 64.4% vs 60.1%
GPQA Diamond: 94.2% vs 91.3%
On the aggregate, particularly for agentic and coding workloads where Claude has historically led, Opus 4.7 extends the gap rather than ceding ground.
One honest caveat: Terminal-Bench 2.0 is a regression. GPT-5.4 scores 75.1% there versus Opus 4.7’s 69.4%. BrowseComp also softens compared to Opus 4.6. Worth knowing if those workflows matter to you.
The 4 changes worth your attention:
1. Vision at 3x resolution
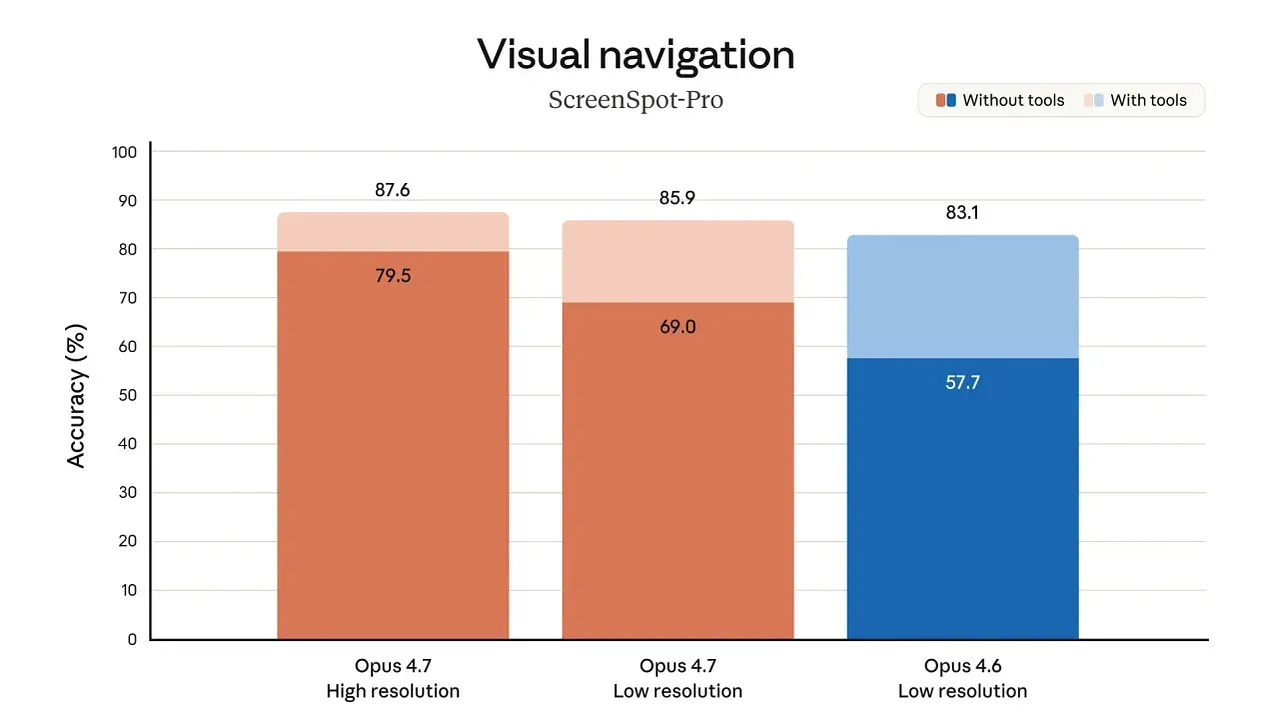
Opus 4.7 accepts images up to 2,576 pixels on the long edge, roughly 3.75 megapixels. Opus 4.6 topped out at 1.15 megapixels. Screenshots, dense diagrams, design mockups, documents: all come through at actual fidelity now.
2. Instruction following is more literal
Where Opus 4.6 interpreted instructions loosely and sometimes skipped steps, Opus 4.7 takes them precisely. This is almost always a good thing. The practical implication: prompts written for older models occasionally produce unexpected results. Re-tune before switching production traffic.
3. A new xhigh effort level
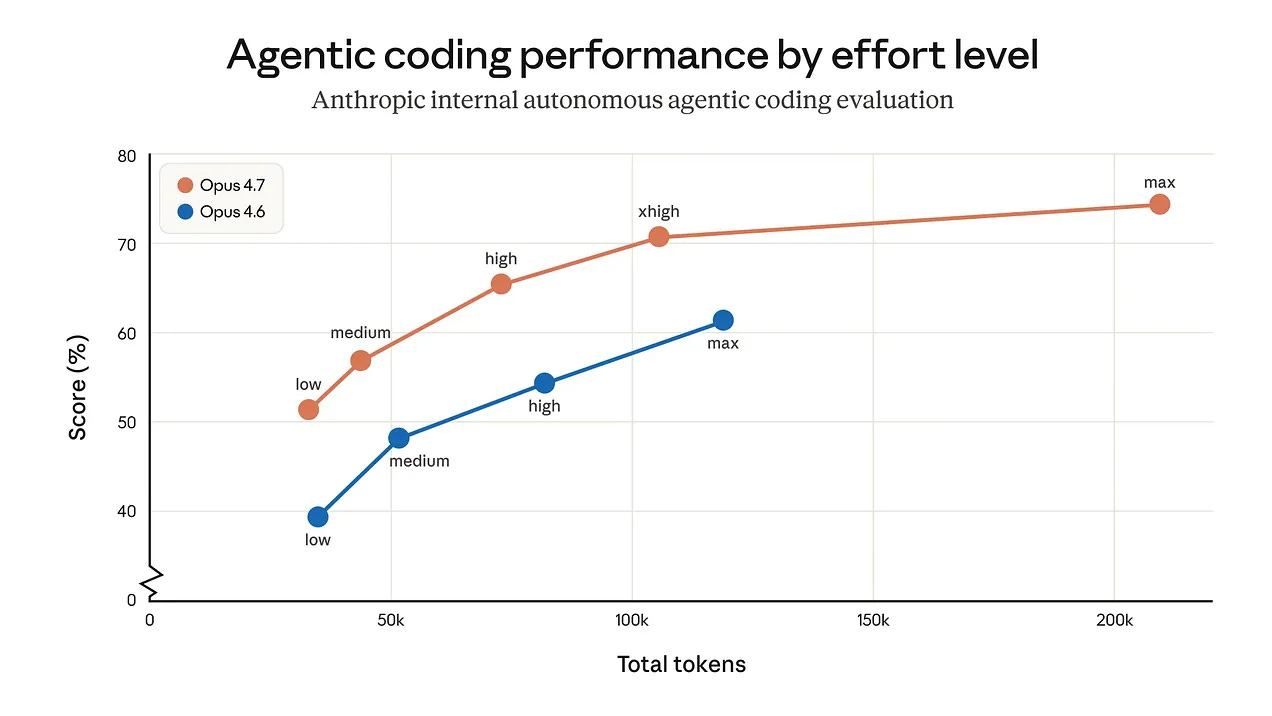
A new setting sits between high and max, giving finer control over the reasoning-latency tradeoff. Anthropic recommends starting with high or xhigh for coding and agentic use cases. Claude Code now defaults to xhigh for all plans.
4. Better file-based memory
Agents that write to and read from scratchpads or notes files across long sessions get noticeably more reliable behavior. Multi-session work that previously lost context now holds it.
The cyber safeguard context:
Opus 4.7 is the first Claude model shipping with automated detection and blocking for prohibited cybersecurity uses. This comes directly from last week’s Mythos Preview and Project Glasswing.
“We stated that we would keep Claude Mythos Preview’s release limited and test new cyber safeguards on less capable models first. Opus 4.7 is the first such model.”
Anthropic, April 16, 2026
Security professionals doing legitimate work can apply to Anthropic’s new Cyber Verification Program.

What is inside the full guide:
The complete 14-benchmark breakdown with the honest assessment of where Opus 4.7 wins and where it does not
The vision upgrade in full: what 3.75 megapixels unlocks for computer use agents, document extraction, and design workflows
The xhigh effort level explained: when to use it, how it interacts with task budgets, and the cost math
Task budgets in beta: the full setup guide with recommended token ceilings per task type
The /ultrareview command in Claude Code: what it flags, how to use the three free reviews Anthropic is offering at launch
The migration guide from Opus 4.6: the two breaking changes that affect token usage and how to retune prompts
The new tokenizer explained: why the same input produces up to 1.35x more tokens and how to manage it
Auto mode for Max users: what it does and when it saves you from interruptions on longer tasks
OPUS 4.7✨ COMPLETE GUIDE:
Keep reading with a 7-day free trial
Subscribe to The AI Corner to keep reading this post and get 7 days of free access to the full post archives.