
OpenAI Just Formalized the Architecture That Separates Expensive AI Teams From Fast Ones
GPT-5.4 mini and nano dropped yesterday. The price gap tells you everything.

$30 per million tokens.
That’s what OpenAI charged for Sora 2 Pro two months ago.
$0.20 per million tokens.
That’s what GPT-5.4 nano costs today.
Same company. Same model family. 150x price difference.

OpenAI calls these their “most capable small models yet.” Built for high-volume workloads where latency directly shapes the product experience. But that framing undersells what actually happened yesterday.
What OpenAI shipped is an architecture decision wrapped in a product release.
The decision: stop routing everything through one expensive model. Build a system where a large model plans and judges, and small models execute in parallel at a fraction of the cost.
They’re calling the small ones subagents.
This is the shift from single-model thinking to multi-model orchestration. The teams that internalize it in the next 60 days will build AI systems that make everyone else look slow and expensive.
What dropped yesterday
GPT-5.4 mini runs more than 2x faster than GPT-5 mini and approaches the performance of the full GPT-5.4 on several evaluations, including SWE-Bench Pro and OSWorld-Verified.
On GPQA Diamond, a test of high-level expertise, mini scored 88.01%. The full flagship scored 93%. A 5-point gap at 3x lower cost.
Community measurements put GPT-5.4 mini at 180-190 tokens per second and nano at 200 tokens per second, compared to 55-60 for the old GPT-5 mini.

The pricing, clean:
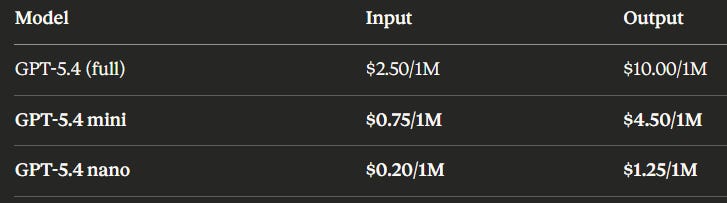
GPT-5.4 nano is cheaper than Google’s Gemini 3.1 Flash-Lite. At $0.20 per million input tokens, you can describe 76,000 photos for $52.
, GPT-5.4 mini ($0.75), GPT-5.4 full ($2.50), Claude Haiku 3.5 ($0.80), and Sora 2 Pro ($30) as of March 2026")
Who gets access
Free + Go users: GPT-5.4 mini in ChatGPT via the “Thinking” option, starting today
Plus / Pro subscribers: Mini as fallback when GPT-5.4 usage cap hits
API developers: Both mini and nano, live right now
Nano: API only. Built for developers delegating tasks to AI agents.
Microsoft: Both models in Microsoft Foundry today
The mental model that actually matters
Old architecture, the way most teams still build:
Prompt → GPT-5.4 → OutputEverything goes to the expensive model. Every classification. Every extraction. Every draft. Every summary.
New architecture, the way fast teams will build starting now:
GPT-5.4 Thinking (planner)
├── nano → classify this document
├── nano → extract these fields
├── nano → rank these results
├── mini → write the summary
└── mini → review this code
→ GPT-5.4: synthesize + final judgment
A large, highly intelligent model plans and makes final judgments. It delegates narrower, repetitive tasks to faster, cheaper models that execute quickly at scale.
Notion already proved this in production. Their AI engineering lead Abhisek Modi confirmed that GPT-5.4 mini matches or beats more expensive models on complex formatting tasks while using a fraction of the computing power.
The cost math on one workflow:
1,000 classification tasks through GPT-5.4 full: $2.50. Through nano: $0.20.
That’s an 8x reduction on a single step. Stack that across an entire pipeline and the savings compound fast.
When to use which

Nano — classification, extraction, ranking, scoring, routing decisions, simple code subagents. Anything short, well-defined, and high-volume.
Mini — drafting, summarizing, code generation, multimodal tasks, tool calling, anything requiring near-flagship quality at a sensible price.
GPT-5.4 full — planning, final synthesis, high-stakes judgment calls, anything where being wrong is expensive.
⭐ PREMIUM — What’s waiting on the other side
Here’s what’s behind the paywall. Specifically.
The Subagent Architecture Playbook — the exact planner/executor design pattern with a workflow diagram you can copy directly into your stack
Model selection decision matrix — every task type mapped to the right model, with reasoning. Copy it into Notion, use it today
Cost templates with real math — 5 workflow types with exact token calculations showing what you save when you route correctly. One shows 65% cost reduction on a content pipeline
Head-to-head comparison — GPT-5.4 mini vs Claude Haiku 3.5 vs Gemini 2.5 Flash-Lite vs Llama 3.3 on Groq. Where each one wins, where each one loses, no hedging
5 workflows to deploy this week — content research pipeline, customer support triage, code review, research assistant agent, data enrichment. Each one has step-by-step model routing and exact prompts
The teams reading this newsletter are already building with these models. The ones without access to this issue are routing everything through GPT-5.4 full and wondering why their API bills keep climbing.
Cancel anytime. First subscribers get 50% off, forever.
1. The Subagent Architecture Playbook
Three rules before touching any workflow:
Rule 1: Atomize before you assign.
Keep reading with a 7-day free trial
Subscribe to The AI Corner to keep reading this post and get 7 days of free access to the full post archives.