
Prompting Is No Longer About Clever Wording
It’s about AI fluency


Most prompting advice is wrong.
People focus on phrasing:
“Add examples”
“Define a role”
“Use step-by-step reasoning”
Those help. But they’re surface fixes.
What separates people getting 10x outputs from those struggling isn’t phrasing.
It’s how they structure collaboration with AI.
Anthropic calls this AI fluency: collaborating with AI effectively across tasks and model generations.
Once you see it, prompting failures stop being mysterious.
The Three Modes (Most People Never Choose Deliberately)
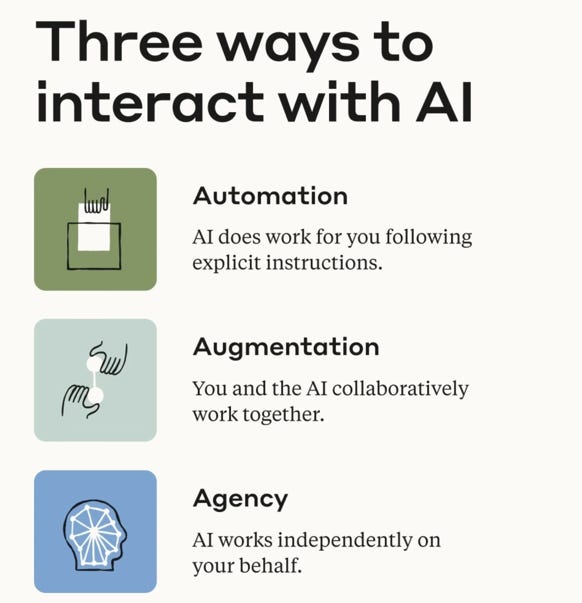
All AI use falls into three modes:
Automation: Give instructions, expect execution
Augmentation: Think alongside the model, iterate
Agency: Delegate goal, let system run autonomously
Most weak outputs happen because of mode mismatch.
You think you’re augmenting. The model hears automation.
→ Result: shallow answer that follows instructions but misses intent.
Or: you think you’re automating. The model interprets agency.
→ Result: it does 10x more than you wanted.
Example of mode mismatch:
"Help me write a blog post about pricing"This could mean:
Brainstorm angles together (augmentation)
Write complete post (automation)
Research, outline, write, edit (agency)
The model guesses. Usually wrong.
Better approach:
Show me 3 different angles I could take on pricing strategies.
For each, give me a hook and thesis.
Then I'll pick one.Now it knows: collaboration, not execution.
Why Better Prompts Fail
Adding more instructions to a fuzzy task creates noise, not clarity.
The bottleneck isn’t the model.
The bottleneck is description.
Description means: Defining what you want the output to be, not just what you want the model to do.
Strong description compresses the problem space.
Weak description forces the model to guess.
Experienced users write shorter prompts that work better.
They define the task well. They don’t micromanage execution.
Example:
Weak:
Analyze my website and give recommendationsStrong:
My B2B SaaS homepage converts at 2%. Industry benchmark is 5%.
What are 3 specific changes to the hero section that could close that gap?
Audience: ops leaders at 100-500 person companies.Same task. But the second one tells the model what matters.
The Four Questions That Fix Most Prompts
Effective description answers:
Who is this for?
What will it be used for?
What constraints matter?
What does success look like?
Simple rule: Describe the output as if a human were producing it.
If a human would struggle to understand the task, the model will too.
Real example of this working:
Before:
Write a cold email for my SaaS productResult: Generic template
After:
Write a cold email for B2B analytics SaaS selling to ops leaders
at 50-200 person companies.
Reference: manual data exports (their current pain)
Position: our product solves that exact problem
Ask: 5-minute demo (low friction)
Length: under 100 words
Tone: conversational, no corporate speakResult: 18% conversion rate (vs 3% industry average)
The difference: Strong description compressed the problem space.
Delegation Changes Everything
Delegation = how much autonomy the model should take
When implicit, models oscillate between hesitation and overreach.
When explicit, reasoning aligns.
Signal delegation through language:
Low autonomy:
Rewrite this to be under 100 words.
Don't change the message.Medium autonomy:
Suggest 3 ways to make this clearer.
I'll pick one.High autonomy:
Research competitor pricing.
Recommend a structure.
Show reasoning.Models respond strongly to this.
Iteration Beats One-Shot Prompting
Good prompting is a loop, not a request:
Model proposes
You evaluate critically
Refine description
Repeat
→ First outputs are rarely final outputs.
This mirrors how teams work with human collaborators.
Example of iteration in action:
Round 1:
Write a landing page for my project management toolGeneric corporate copy about “streamlining workflows”
Round 2:
Too generic. Our angle: most PM tools are too complex.
Ours is intentionally simple - projects, tasks, deadlines.
Rewrite with that positioning.Better, but missing specificity
Round 3:
Good direction. Now add:
- Target: solopreneurs and small teams (2-10 people)
- Previous tool: tried Asana, found it overwhelming
- Write hero section only
- Under 50 words
- End with problem we solve, not featuresThis version shipped.
Most people give up after Round 1.
Iteration is where quality happens.
What’s Behind the Paywall
Most people understand these concepts.
They don’t know how to apply them.
Premium gets you:
✓ The Complete Mental Model
How to think about prompting across all models. The 3 modes mapped to real use cases.
✓ Prompting Techniques by Mode
Specific patterns for automation, augmentation, agency. What works, what fails, why.
✓ The 4-Question Framework in Practice
How to write prompts that compress problem space. Real examples with before/after.
✓ Delegation Patterns
Templates for signaling autonomy level. Collaborative, execution, and agentic task structures.
✓ Iteration Systems
The loop that turns mediocre outputs into excellent results. How pros refine prompts.
✓ 3 Reusable Templates
Copy-paste patterns for:
Collaborative analysis
Careful execution
Bounded agency
✓ Common Failure Modes
The 4 mistakes killing your prompts. How to diagnose and fix each.
✓ Practice Framework
4-week system to build AI fluency. Exercises that compound.
This is a reference guide, not a one-time read.
The difference between 40% and 90% of AI’s capability is knowing these patterns.
Most people write prompts that sometimes work.
A few understand the system that makes them work consistently.
Which one will you be?
Premium: The Complete AI Fluency System
Keep reading with a 7-day free trial
Subscribe to The AI Corner to keep reading this post and get 7 days of free access to the full post archives.