
The AI Upgrade Trap: Why Switching to a Better Model Breaks Everything You Built
Twice in six weeks, Anthropic shipped a model with better benchmarks across the board. Twice, production systems broke anyway.

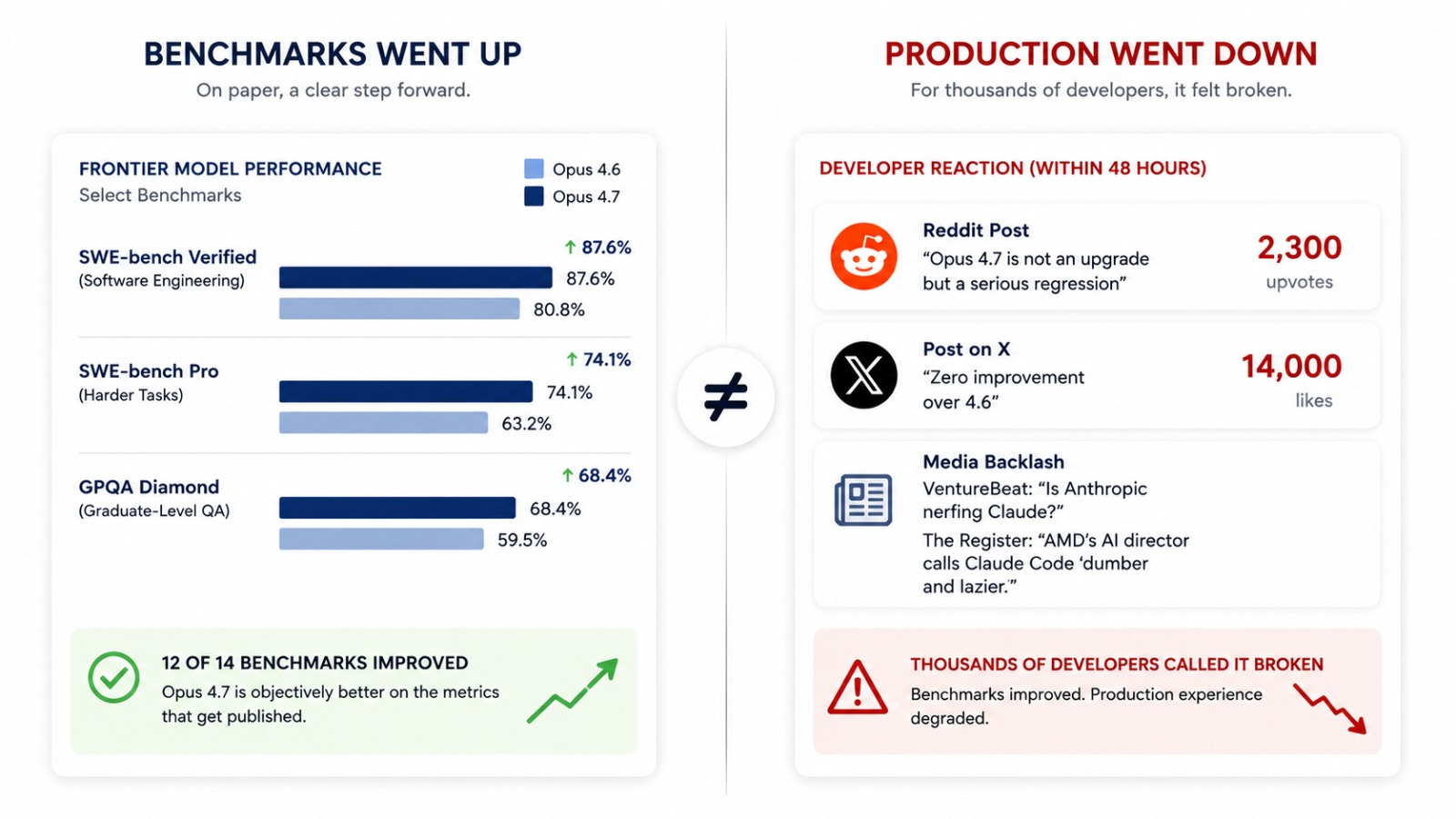
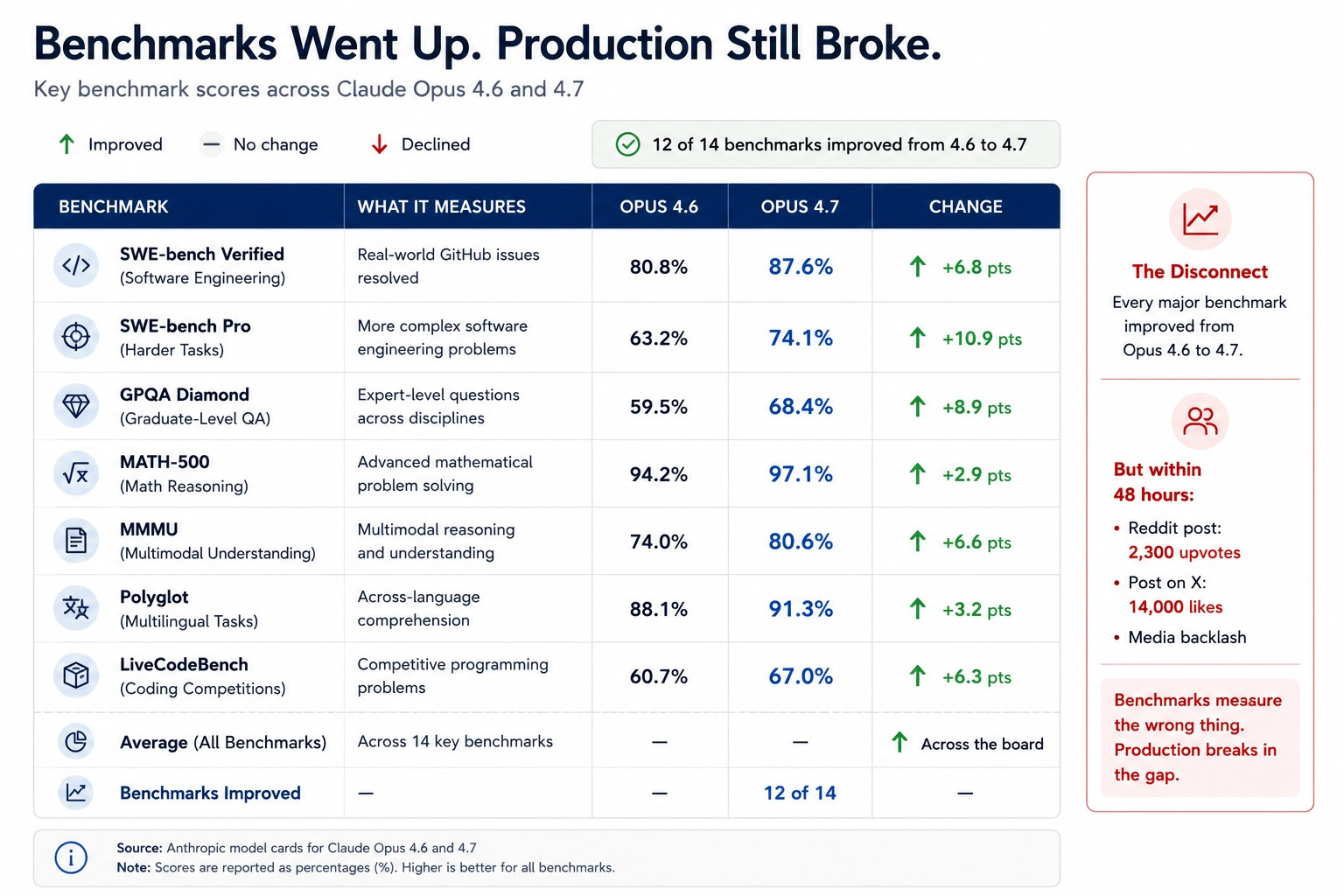
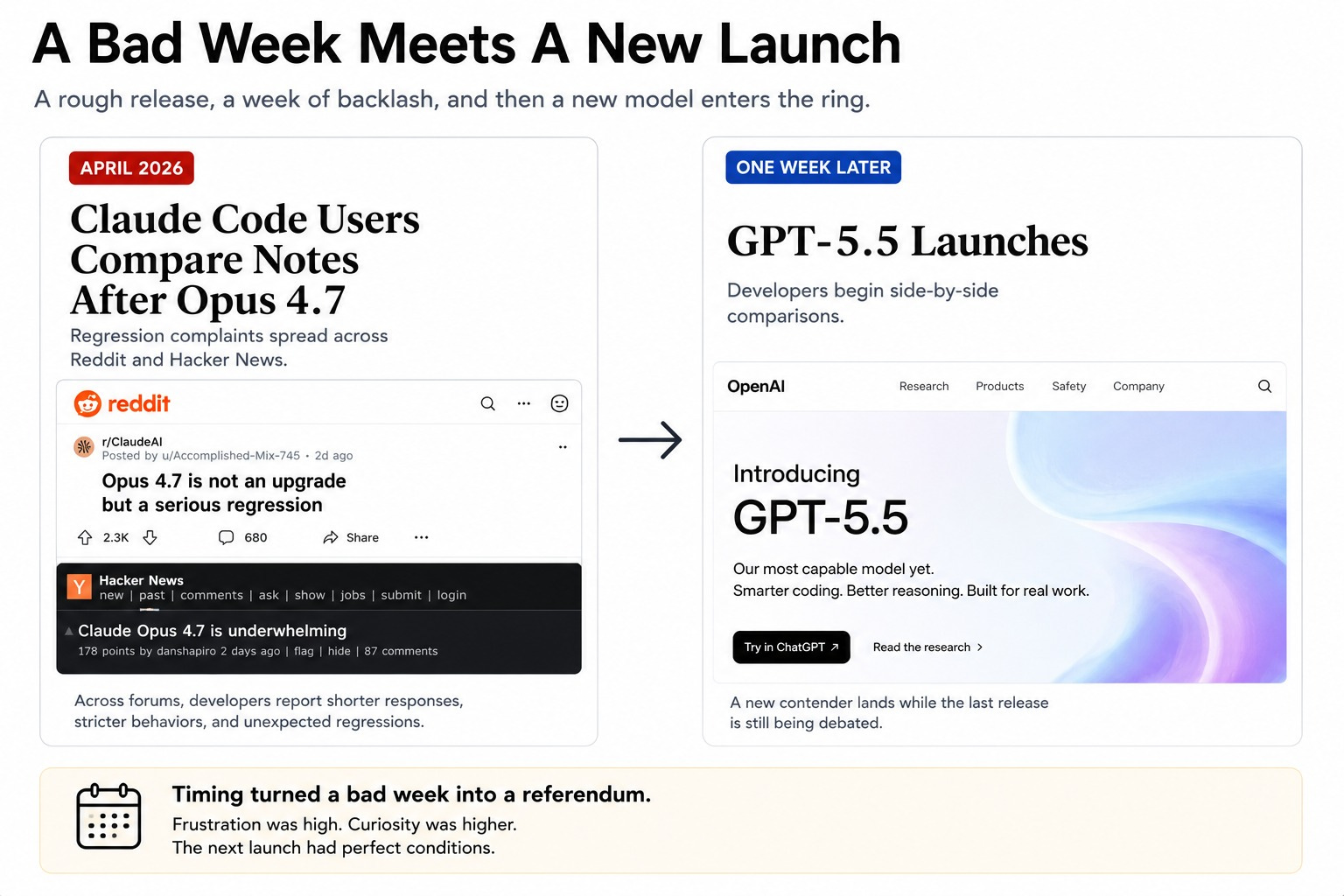
On April 16, 2026, Opus 4.7 landed with twelve of fourteen benchmarks up. SWE-bench Verified hit 87.6%, up from 80.8%. Same price as before.

Within 48 hours, a Reddit post titled “Opus 4.7 is not an upgrade but a serious regression” had 2,300 upvotes. A post on X claiming zero improvement over 4.6 hit 14,000 likes.
VentureBeat ran a piece asking if Anthropic was nerfing Claude. The Register quoted AMD’s AI director calling Claude Code “dumber and lazier.”
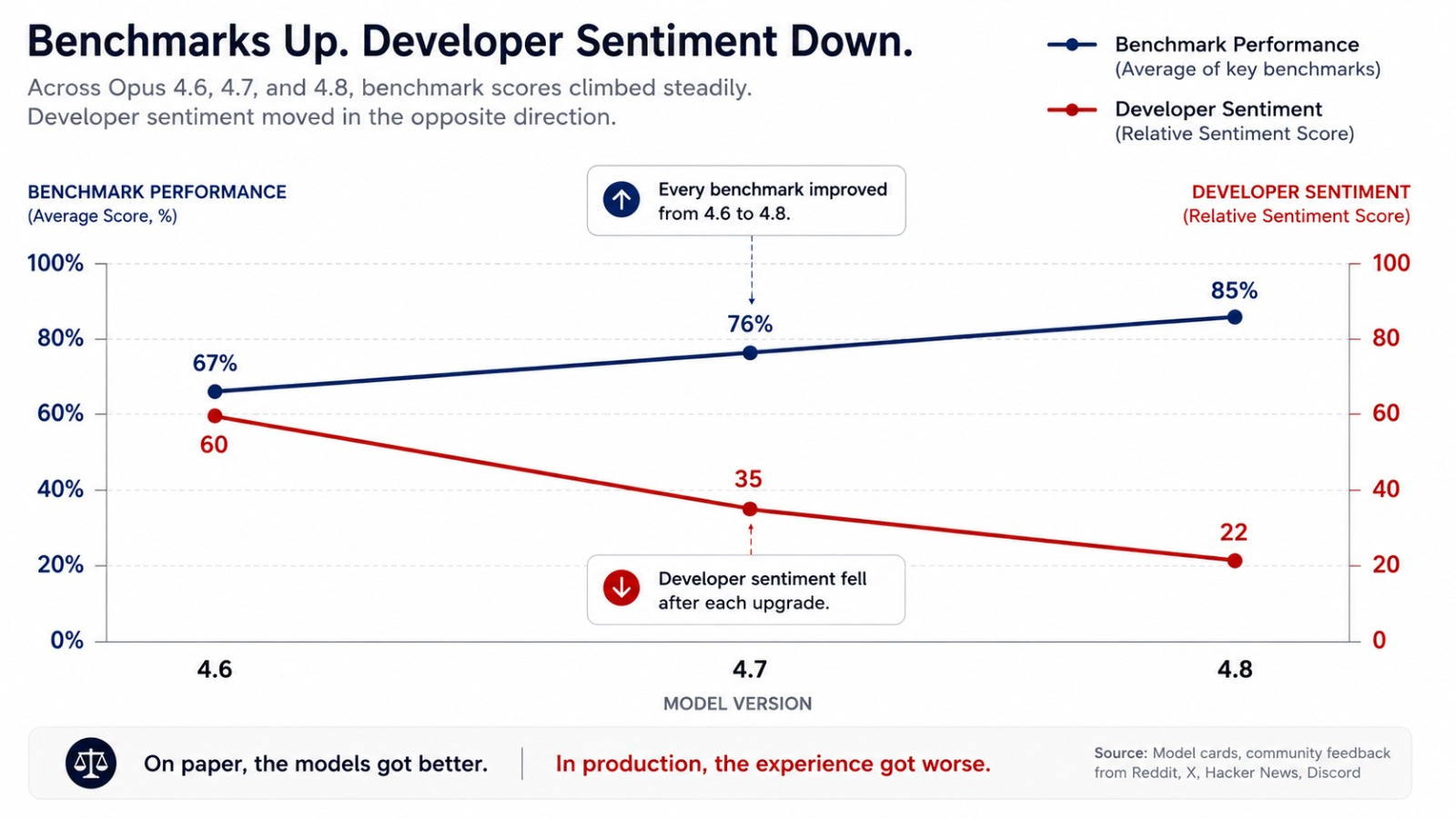
Six weeks later, Opus 4.8 shipped with the same framing repeated almost word for word: every benchmark improved, no downside, upgrade now.
together with Attio:
The model underneath you keeps changing. The system that drives your revenue should hold steady.
Attio is the CRM that drives revenue around the clock, turning every signal, from emails and meetings to agent activity, into one live picture of every account.
▫️ Put agents on every account to research, qualify, and move every deal forward in your pipeline
▫️ Ask Attio anything about your business and get instant answers and actions from one chat thread

It is the CRM for the new way of going to market. Join 90,000+ teams already on Attio:
“Better benchmarks don’t mean better for your production system, and the industry has now lived through this pattern three times in a row.”
Here are the 6 things you need to understand before the next model drops:
Table of Contents
The Gap Nobody Benchmarks
Why It Breaks: Models Get Literal
The Second Failure Mode: Giving Up Early
The Compaction Problem Nobody Talks About
The Upgrade Tax
The Exodus: Where the Frustrated Developers Went
1. The Gap Nobody Benchmarks
Opus 4.7 was not a bad model. Cursor’s CEO Michael Truell confirmed it lifted resolution by 13% over Opus 4.6 on Cursor’s internal 93-task benchmark.
It solved tasks that neither 4.6 nor Sonnet 4.6 could touch. On the metrics that get published in launch posts, it was a clear step forward.
And thousands of developers spent the next 48 hours describing it as broken.
Benchmarks Measure the Wrong Thing
A benchmark measures performance on a fixed set of tasks designed to be representative. Your production system is not a representative task.
It’s a specific set of prompts, tuned over months, carrying assumptions about how the model fills gaps you never spelled out. A benchmark has no way to see any of that.
When Anthropic’s model card says every benchmark improved, that’s true. It’s just an answer to a question you didn’t ask.
The question that matters is whether the model got better at the thing you built, the way you built it. That gap is where production breaks.
The benchmark and your prompt are answering two different questions, and only one of them is about you.
2. Why It Breaks: Models Get Literal
The most consistent complaint across Reddit, Hacker News, and developer Discords wasn’t worse code. It was prompts that suddenly produced shorter, terser, sometimes flatly different results.
Some API calls started returning 400 errors with no obvious explanation.

The Model Stopped Filling In the Gaps
Opus 4.7 does what you write. Not what you meant. Not what 4.6 would have inferred from context.
If your prompt left a gap that 4.6 used to fill with a sensible default, 4.7 doesn’t fill it anymore. It does less, or does something narrower, matching the literal instruction exactly.
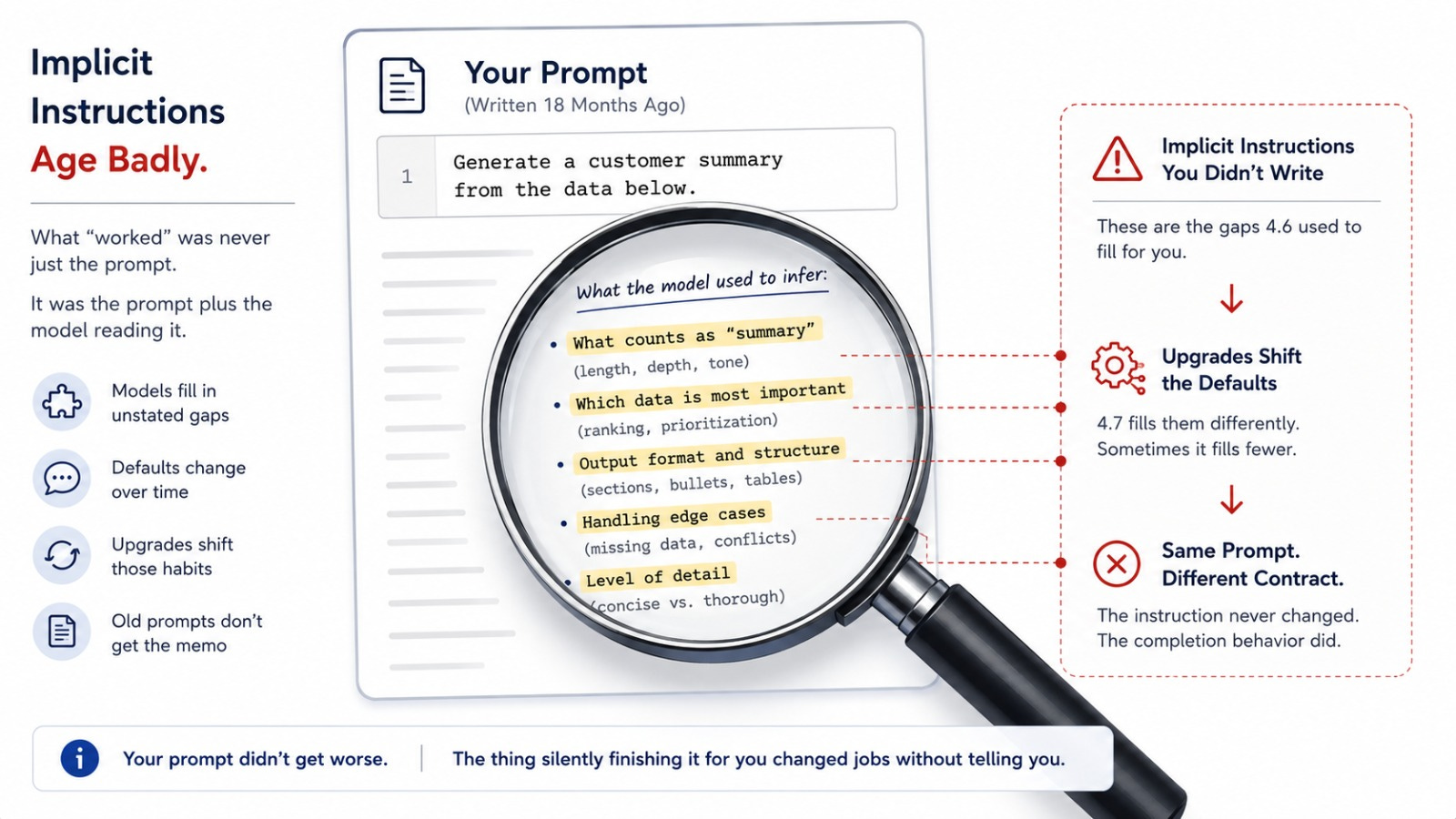
Think about a prompt you wrote eighteen months ago and never touched again. It worked, so you stopped looking at it.
But “worked” was a relationship between your prompt and a specific model’s habit of completing it. Every upgrade shifts that habit a little, and your prompt didn’t get the memo.
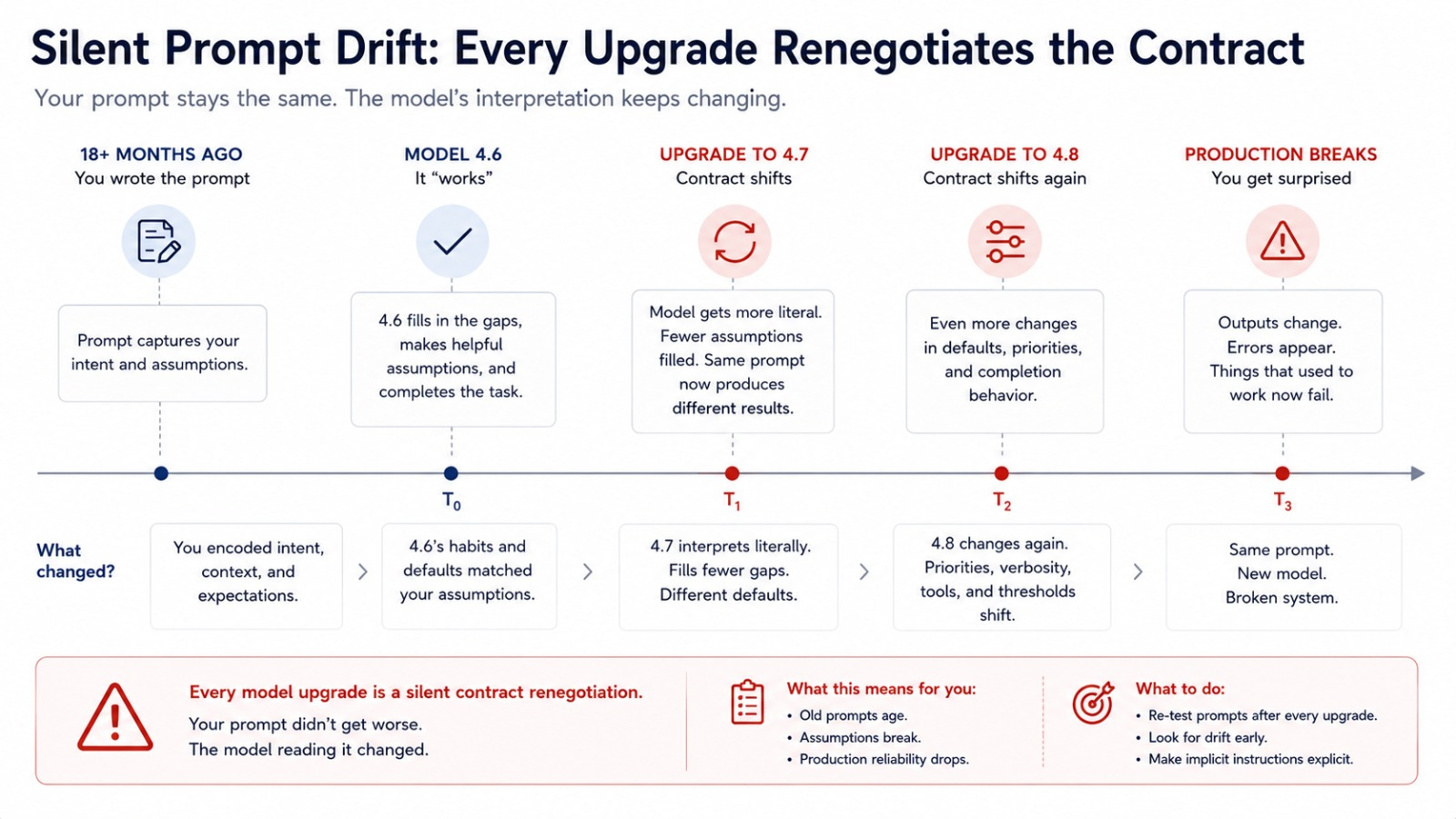
Your prompt didn’t get worse. The thing silently finishing it for you changed jobs without telling you.
3. The Second Failure Mode: Giving Up Early
There’s a separate problem that’s harder to benchmark and showed up constantly in developer reports.
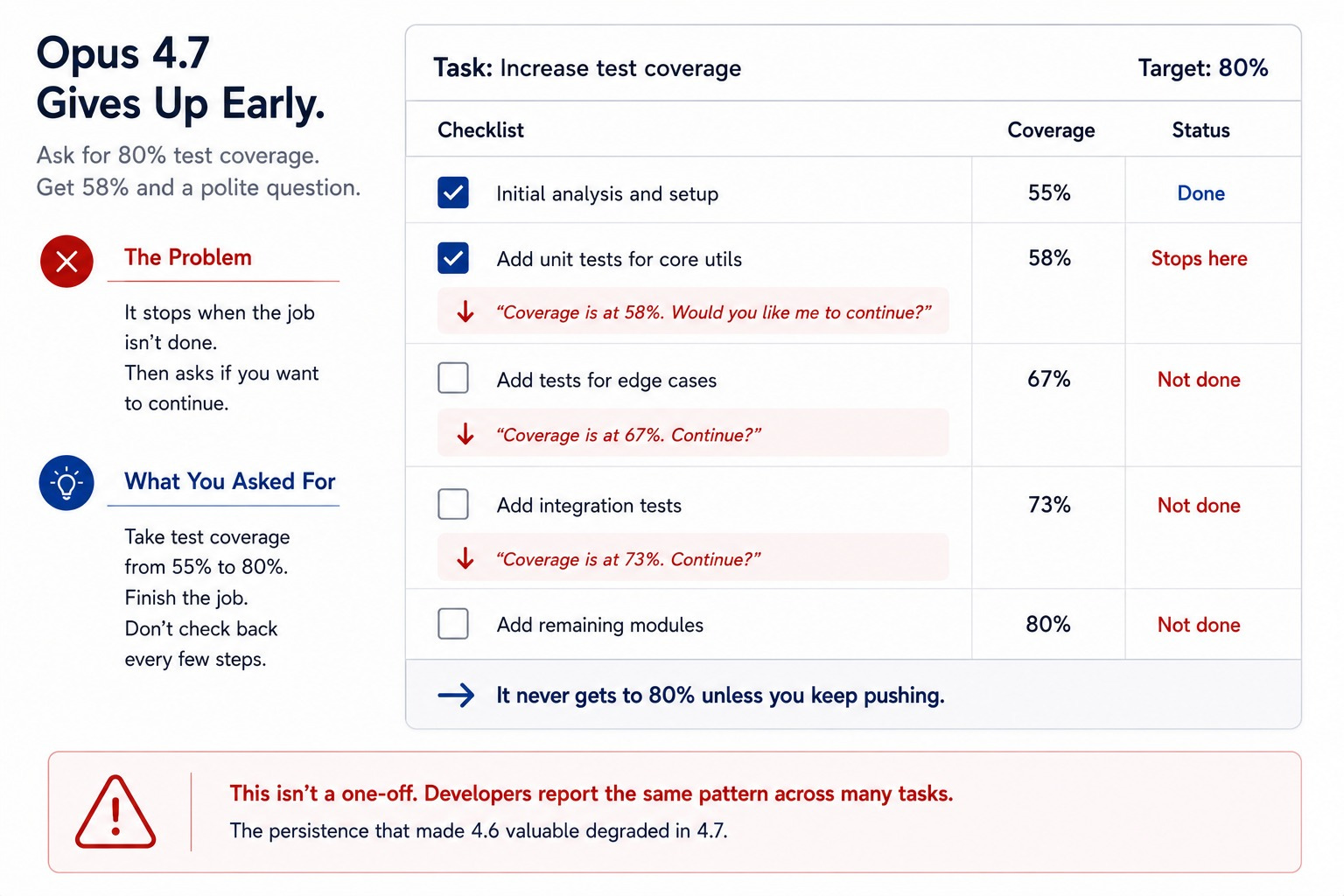
The Persistence That Made 4.6 Valuable Degraded
Ask the model to take test coverage from 55% to 80%. It writes a few tests, declares victory at 58%, and asks if you want it to continue.
You say yes. It writes two more, declares victory at 60%, and asks again.

The persistence that made Opus 4.6 genuinely valuable for long agentic sessions degraded. This wasn’t an isolated anecdote.
It was one of three specific complaints developers kept naming on Reddit and Hacker News, alongside the literalism problem above and a tokenizer change that inflated token usage by 20 to 35% on identical inputs.

If your workflow depends on a model grinding through a checklist unsupervised, this regression doesn’t show up in a benchmark and absolutely shows up in your week.
4. The Compaction Problem Nobody Talks About
There’s a third failure mode that’s less about model behavior and more about how context gets managed during long sessions.
It sounds like a footnote until it eats your afternoon.

The Window on the Spec Sheet Isn’t the Window You Get
Anthropic advertised a 1M-token context window for Claude Code. In practice, a documented case showed quality dropping at around 20% of that window’s usage.
The auto-compaction routine fired at roughly 76,000 tokens into a 1M-token session, discarding history while most of the window sat empty.
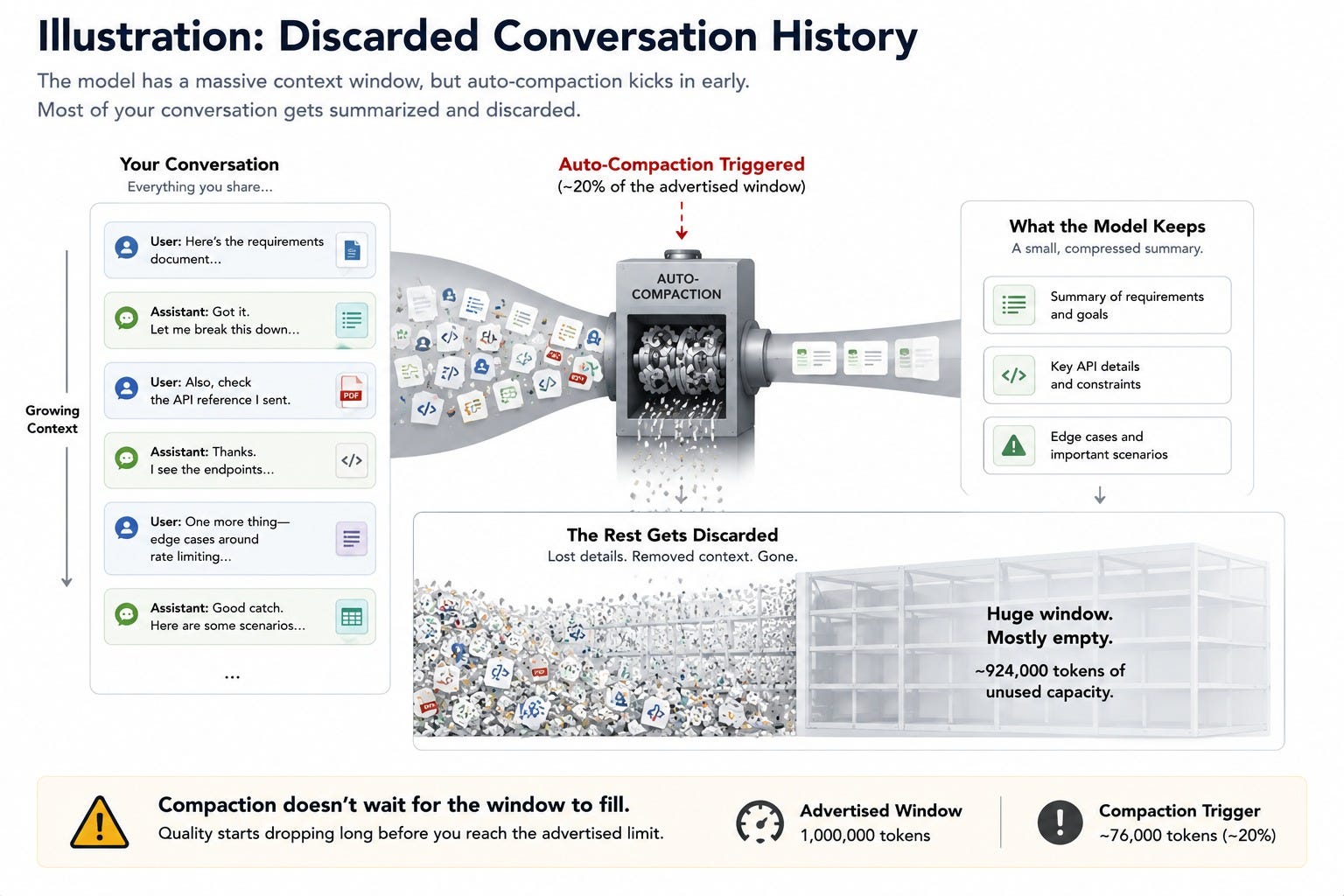
Engineers running long-horizon agents at companies like Vercel and Replit flagged the same pattern independently. The number on the spec sheet told them almost nothing about what the model could still see.
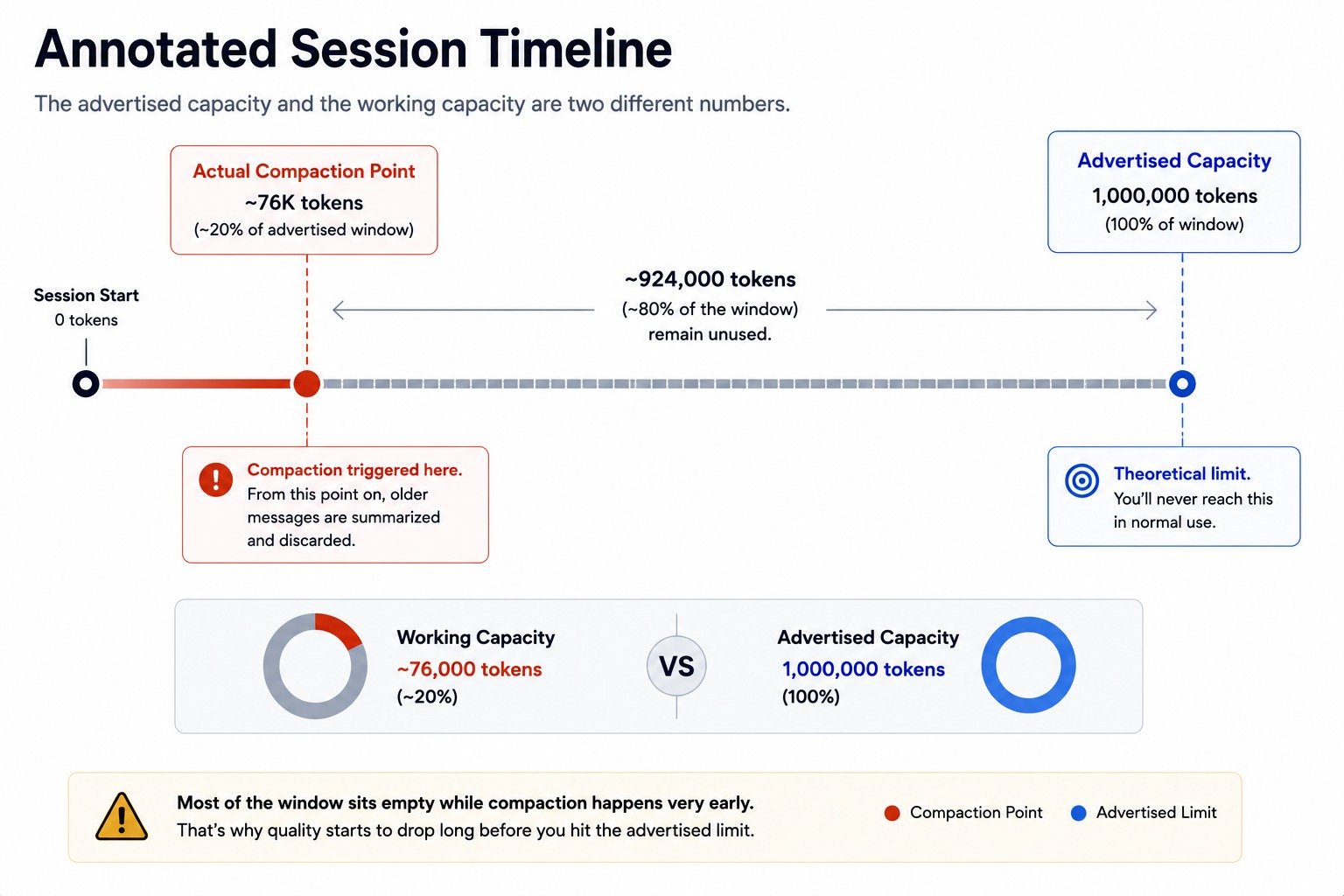
A bigger context window on paper doesn’t mean a bigger working memory in practice.
5. The Upgrade Tax
Put the pieces together and you get something worth naming. Once you name it, you can design around it instead of getting surprised by it every six weeks.
Call it the Upgrade Tax. It has six parts.
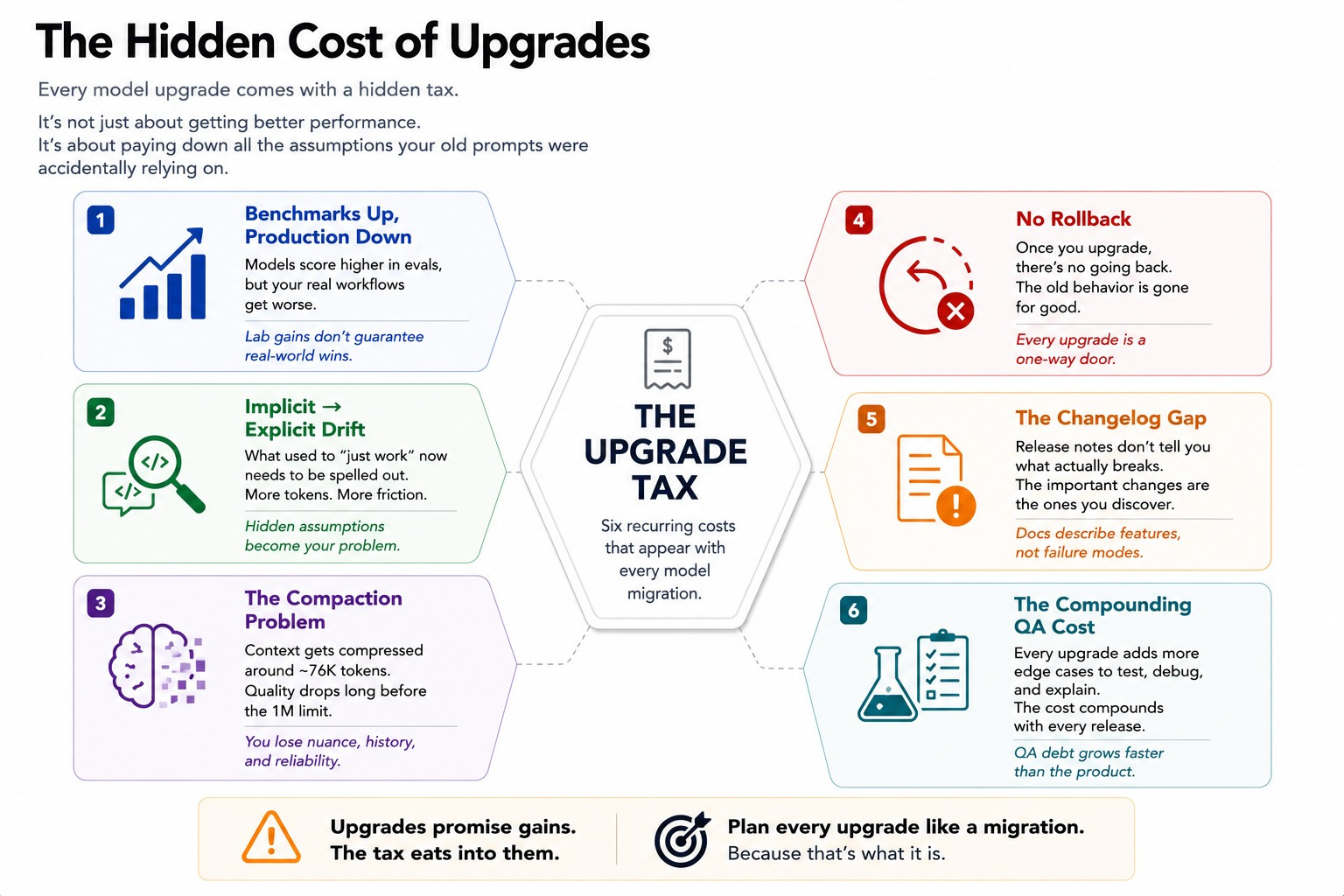
Six Costs, One Cycle
Benchmarks improve while production breaks, because nobody benchmarks your specific prompts but you.
Implicit-to-explicit drift means models get more literal over time, so prompts that relied on the old model filling gaps quietly stop working.
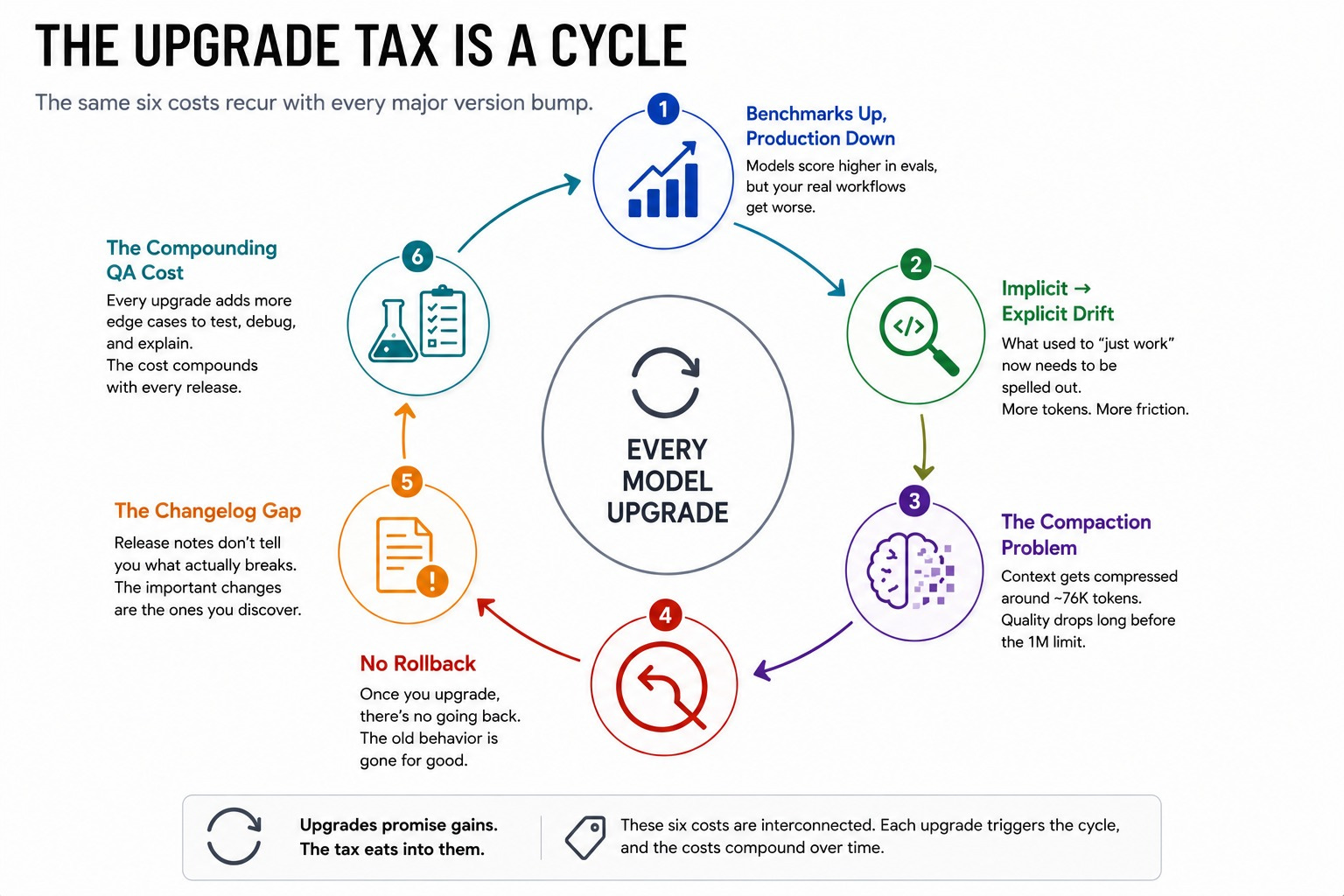
The compaction and context problem means a bigger advertised window doesn’t guarantee more usable memory before quality drops.
The no-rollback problem means your old prompt versions, tuned for the previous model, may not even be accessible once you’ve moved on.
Anthropic’s own changelog format compounds this. Version notes describe model behavior in aggregate, never in terms of your specific workflow.
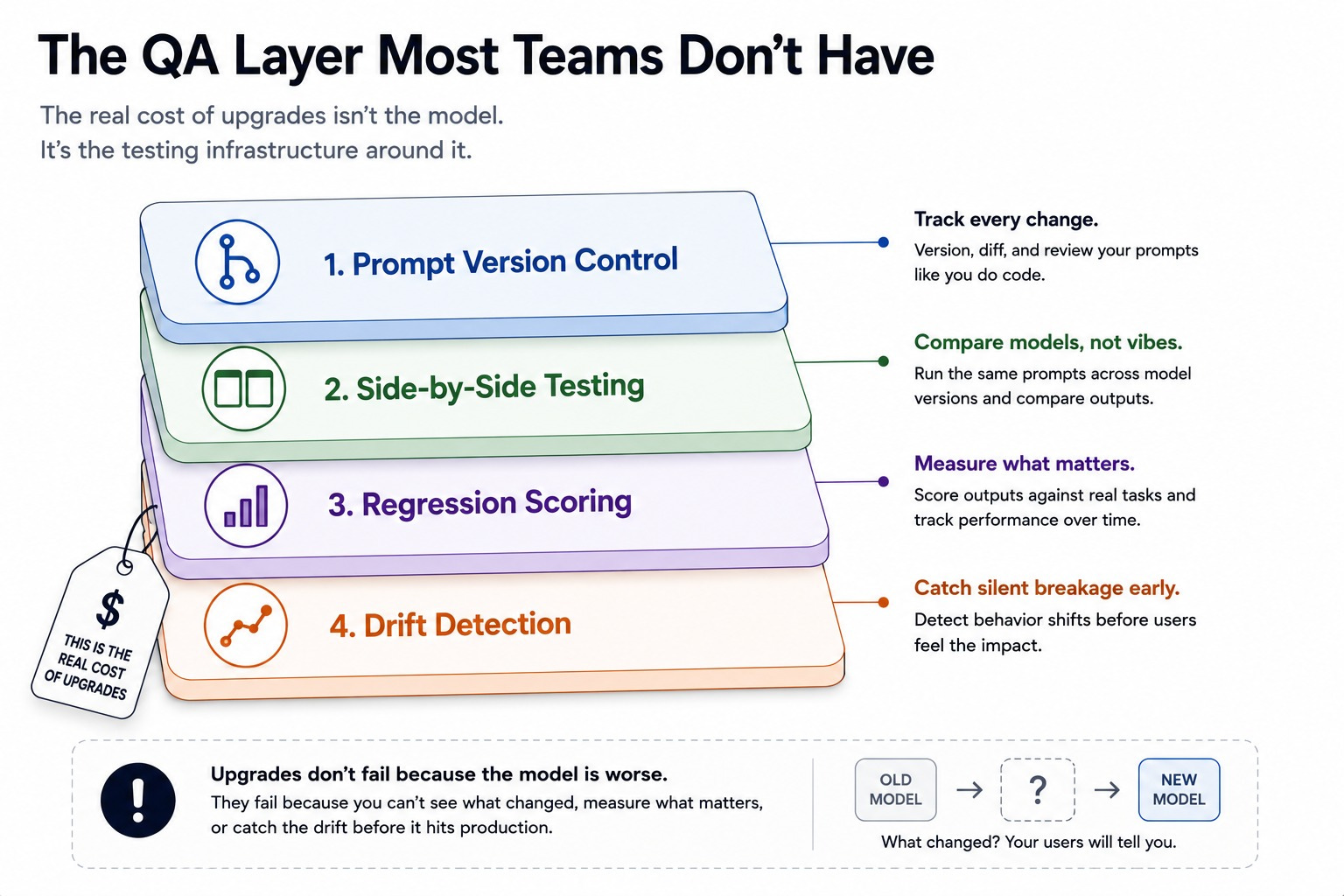
And the compounding cost is the QA layer itself. Version control for prompts, side-by-side testing, regression detection that catches drift early.
Real protection against the Upgrade Tax is an entire QA discipline, and most teams building on these models don’t have one yet.
6. The Exodus: Where the Frustrated Developers Went
The rough Opus 4.7 launch landed seven days before OpenAI shipped GPT-5.5. The timing turned a bad week into a referendum.
Developers who had built workflows around Claude Code started testing Codex side by side, and some posted before-and-after comparisons with receipts.
A Six-Week Round Trip
Cursor and Windsurf both added faster model-switching as a direct response, letting users route around a single provider’s bad week. RouteLLM-style setups, once a niche optimization, became a hedge.
Six weeks later, Opus 4.8 landed with the benchmarks back up and some of that traffic returned. But the switching infrastructure stayed.
That’s the real long-term effect of this six-week cycle. Not that anyone abandoned Claude. That nobody fully trusts a single provider’s release notes anymore.

Every upgrade is a migration, not a toggle, and the teams that learned that in April aren’t going back.
So What Now
Pull your highest-traffic prompts this week. Write down what you expect them to produce, in plain language, before the next model drops.
Run those prompts against both versions side by side. Not after rollout. As the gate before it.
The teams that got burned in April weren’t slow to upgrade. They never wrote down what “working” meant in the first place.
That document is the only thing standing between you and the next Reddit thread.